| [Standard query | Lemma query | Browse a file | Word lookup | Scan keywords/titles | Explore genre labels | Frequency lists | User settings | Query history | Create/Edit subcorpora | Post-query options ] |
Standard query |
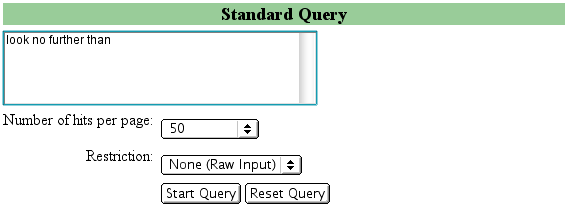
A Standard Query is used to search for words or phrases in the whole corpus or in the full spoken or written components. Standard queries range in complexity from single word searches to more advanced options concerning what to look for and in which parts of the corpus to do the searching:
Performing a standard query |
Restricting a query using metatextual categories |
You can choose to restrict the query to the whole spoken or written component of the corpus by opening the drop-down menu for Restriction and changing the selection from 'None (Raw Input)' to 'Spoken texts' or 'Written texts' respectively.
If you need more control over text category restrictions, choose either 'Written texts' or 'Spoken texts' in the left-hand menu bar under Standard query. Here you can select such metatextual categories as the date of publication of the text, the age, sex and other characteristics of the author (if you selected 'Written texts'), the age, sex and so on of the speaker (if you are in 'Spoken texts') or the respondent.
The following screenshot shows how to search for the word lovely in books belonging to the text domain 'Social science' (not all available categories are shown below).

In the 'Written texts' or 'Spoken texts' pages, you can leave the query string box empty and only select metatextual categories. The query result will then be a list of text files corresponding to the selected criteria. This list can be used to create a subcorpus. See Create/edit subcorpora for further details.
Please note: In the 'Spoken texts' query page, please note the difference between categories which apply to Respondents (i.e. the person who recorded the conversation) and those which apply to Speakers. In the former case, selecting "Age of Respondent: 35-44" will not restrict your query string to utterances produced by respondents within this age range, but rather match all instances of your query string in texts recorded by the corresponding respondents. You may therefore retrieve instances which are spoken by people belonging to a radically different age band.
Note: Due to technicalities to do with the way genre categories are encoded in the BNC headers, it is not possible to restrict searches to specific BNC genres at the outset. Instead, you need to define a subcorpus first, which can then be chosen as a post-query filter (i.e. after an initial search on the whole BNC). You may also find this subcorpus feature useful if you wish to regularly or repeatedly run queries on specific subsets of the BNC (without having to re-specify your metatexual restrictions).
Finding part-of-speech tags |
To find a word together with its part-of-speech tag, type the word first, followed by '=', and the tag. E.g.
can=VM0 finds can tagged as a modal auxiliary can=NN1 finds can tagged as a singular common noun
(Note that the last character is a zero, not the letter O!)
A good way of finding out the different part-of-speech tags for a word is to use the Word lookup function (where you can enter a word and list all POS tags with which it occurs in the corpus).
For a detailed description of the tagset, as well as technical information about the tagging of the BNC World Edition, see Leech and Smith.
N.B. It is not possible to do an initial search for part-of-speech categories on their own - only word-tag combinations can be entered in the search box.
Querying contracted forms and multiword units |
Queries containing contracted forms (such as doesn't, you've, he'll, she'd've) or fused forms (e.g. wanna, dunno, gimme) have to be treated with special care. In the BNC contracted forms have been separated into their component parts. To find them in BNCweb, enter them as separate words in the query string box, with the enclitic part enclosed in double quotes, e.g.
does "n't" he "'ll" she "'d" "'ve"
Note that each part of a contracted form also has its own part-of-speech tag. This is useful for distinguishing ambiguous forms, like 's and 'd:
she ("'s"=VBZ) (= she is) she ("'s"=VHZ) (= she has)
Fused forms are broken into component parts, in a way that is rather more arbitrary, as the table below shows. Double quotes are not required when looking for these items. A more complete list of contracted forms and associated tags in BNC2 is provided by Lancaster University.
| What you are looking for | Query strings to enter | |||
| Contracted form | Full form | First word | Second word* | Third word |
| they've | they have | they | "'ve" | |
| he'll | he will | he | "'ll" | |
| she's | she has | she | ("'s"=VHZ) | |
| she's | she is | she | ("'s"=VBZ) | |
| doesn't | does not | does | "n't" | |
| won't | will not | wo | "n't" | |
| ain't | ? | ai | "n't" | |
| gimme | give me | gim | me | |
| gonna | going to | gon | na | |
| innit | isn't it | in | n | it |
*If you want to add a POS tag to an item enclosed in quotation marks, you must put parentheses around it.
The reverse situation is found for so-called Multiword units: several orthographic words are given a single POS tag and they are consequently treated as a single unit. Further information on the principles of tokenization can be found in the Automatic POS-tagging manual and a complete list of multiword units is found here. Some examples are:
| What you are looking for | Query strings to enter | |
| Multiword unit | Query string | POS-tagged |
| a bit | "a bit" | "a bit"=AV0 |
| even though | "even though" | "even though"=CJS |
| ad hoc | "ad hoc" | "ad hoc"=AJ0 "ad hoc"=AV0 |
| hocus pocus | "hocus pocus" | "hocus pocus"=NN1 |
| in front of | "in front of" | "in front of"=PRP |
| lo and behold | "lo and behold" | "lo and behold"=ITJ |
| no matter what | "no matter what" | "no matter what"=DTQ |
| no one | "no one" | "no one"=PNI |
Note that in some contexts a word-sequence may function as a multiword unit, while in others it does not. Cf.
"which they would not have done <w PRP>but for the presence of the police"with
"<w CJC>But <w PRP>for years now darkness has been growing"
Quotation marks are not required when looking for the latter.
Note: A search for front will also retrieve all instances of front which are part of the multiword unit in front of. This was not the case for the version of the SARA server distributed with the BNC1 release.
Specifying accented and other special characters |
A number of accented and other "special" characters occur in the BNC. While they are usually displayed correctly in the browser windows, it is important to remember that if any character with diacritics (such as é, ö, Ü, â etc.) or other special character is part of your query string, the word containing it has to be enclosed in double quotation marks. Thus to look for occurrences of Zürich in the corpus, remember to enter
"Zürich"
and not
Zürich
in the query box. If you forget to put in the quotation marks, the first special character is likely to terminate the query string, causing undesired results.
Advanced queries |
BNCweb allows more complex queries than those already discussed. It can, for example, find partly-specified word patterns, sequences with optional characters or words, and words occurring in proximity with one another:
CQL is short for Corpus Query Language, SARA's own internal command language. Any query conforming to CQL syntax can be entered in the search box. This can be used to refine a query in various ways:
| Query string | Desired effect |
| (dog|cat) | finds either the word dog or the word cat |
| $Dog | finds the word Dog (but not dog) |
| @dog | find the word dog in headers as well as in texts |
| (cat)_(dog) | finds three-word phrases of which the first word is cat and the last is dog |
| cat*dog | finds occurrences of cat followed anywhere within the same document by dog |
| cat#dog | finds occurrences of cat followed or preceded by dog anywhere within the same document |
| cat*dog/10 | finds occurrences of cat followed by dog within ten words |
| cat*dog/<s> | finds occurrences of cat followed by dog within a single s element |
| cat*dog/<u> | finds occurrences of cat followed by dog within a single u element |
Note: CQL-syntax currently does not allow a combination of several scopes as for example in "(cat#dog/10)/<s>" which is an attempt to find occurrences of cat followed by dog within ten words of the same <s>-unit.
Using a special query prefix, you can instruct the program to search one or more texts whose three letter file identification you already know. The following example tells BNCweb to look for instances of the string want in the BNC documents G42 and AKX only:
<bncDoc id="G42" id="AKX">#(want)
There is a limit for the length of this type of query string (about 10 text IDs). As a consequence, it is not possible to use this query syntax for searching hundreds of texts at the same time. Use the Subcorpus feature for this instead.
Users more familiar with CQL and the BNC text category codes may also prefer to
express other types of queries in the compact notation of CQL:
<catRef target=wrimed1>#<catRef target=wridom4>#(lovely)
This will produce the same result as the query shown in the screenshot above (under Restricting a query using
metatextual categories), i.e. it will restrict searches of lovely to books within the social science domain.
Queries in BNCweb can be made in the form of regular expressions (or patterns). Some examples are:
{critici[sz]e} finds criticise and criticize {in(ter)?dependent} finds independent and interdependent {spr[^eo]ngs?i?n?g?} finds spring, springs, sprang, sprung, and springing.
There are countless introductions to regular expressions on the internet. Although not everything will work in BNCweb, the basics will certainly be supported.
PLEASE NOTE that regular expression queries must be put within curly brackets. There is a certain overlap between CQL-syntax (see above) and regular expression syntax (e.g. the use of the vertical bar (|) for indicating alternation). As a consequence, some regular expressions may produce the required result without having been placed within curly brackets. In most cases, however, you are more likely to see a syntax error message...
Regular Expressions are useful for searching text. They can be used the same way one would search something with the simple Find command in a word processor.
1) Example: hit, hat, hot, hut, shut, etc.
Simple case: each character stands for itself. Easy but tedious!
Unlike the Find... command Regular Expressions allow a search for variable patterns.
2) Example: h.t
Here the full-stop does not stand for itself. The full-stop indicates to the computer that any character may be encountered at that position. This means that the pattern will find hit, hat, hot, hut, etc. The full-stop in the pattern is an atomic regular expression; i.e. it stands for one (1!) character, which in this case may be any character.
An atomic regular expression stands for one character. The full-stop in the example above is an atomic regular expression. It represents one character. Thus the regular expression h.t does not match words like heat, because heat is not defined by the search: Find text where the letter h is followed by any one letter and the letter t.
Often it doesn't make sense to allow all characters. We might for example be interested in vowels only. It is possible to require character sets.
3) Example: h[aeiou]t
Character sets are written as a list of characters in square brackets. We might also encounter cases in which we would like to express our wish to allow any character except one. It would be very tedious to enumarate all other characters.
4) Example: h[^ae]t
The caret (^) negates the character set. Thus [^ae] will match all characters except a or e.
The minus sign (-) may be used to indicate a range of consecutive ASCII characters; for example, [0-9] is equivalent to [0123456789].
5) Example: h[aeiou]+t
The plus-sign means that the expression to its left may occur 1 or more times. It will therefore also match heat, hoooooooooot but not ht.
| Quantifier | Explanation |
| * | Match 0 or more times |
| + | Match 1 or more times |
| ? | Match 1 or 0 times |
Brackets can be used to group several atomic regular expression into one regular expression. This is especially useful for quantification.
6) Example: (green|yellow|mauve|red)
This is the way to express alternation. It finds either green or yellow or ....
Alphanumeric characters (i.e. letters and digits) always stand for themselves. To use them as expressions meaning something else they
must be preceded by a backslash (\). Other characters may or may not stand for themselves. It is therefore safer to precede
them with a backslash to avoid undesired results.
The following characters must be preceded by a backslash to stand for themselves:
+ ? . * ^ $ ( ) [ ] {} | \
Notes |
| [Standard query | Lemma query | Browse a file | Word lookup | Scan keywords/titles | Explore genre labels | Frequency lists | User settings | Query history | Create/Edit subcorpora | Post-query options ] |