
| [ BNC query result | File and speaker information | Sort | Thin | Subcorpus | Distribution | Collocations | Tag sequence search | Delete hits | Save current hits | Download | Main page options ] |
Collocations |
Using the Collocations feature, you can find lexical items (and grammatical categories) that commonly co-occur with your search item, provided that they meet frequency criteria that you have defined. The output format of the collocation feature is a table of items which are ranked by collocational strength. This ranking should not be confused with a pure frequency ranking (i.e. items which most frequently co-occur with your search item may in fact not be found highest in the table.) Various statistical measures exist to calculate collocational strength. Before using the data produced by the collocation feature in your research, it is highly recommended that you consult some of the relevant literature on collocations. A few useful references are given at the end of this section (see footnote 3).
There are 3 basic steps to this function:
Retrieving collocations |
Step 1: After running an initial word, phrase or lemma query, you can choose to look for collocational patterns. The screenshot below shows the results window after running a query for the word ballistic, and shows an opened drop-down menu towards the right, with the option "Collocations" highlighted. Select this option and then press the "Go!" button:
Step 2: You will now see a screen with the following options (this is not a real screenshot, but a slightly altered one, with an additional column of explanatory notes). At this stage, you are asked to choose some options before the collocational search is set in motion. The choices you make here will determine the results you get and the options which will be available in the next step. Most of time, the default options (shown below), are fine (in which case just press 'Submit' to go to the next step).
| BNC Collocation Settings | Explanation/Notes | |
| Calculate over sentence boundaries: |
|
If set to 'yes', allows you to find collocations
which cut across sentence boundaries (anything marked up with
<s> in the corpus; largely coincides with full-stops,
exclamation/question marks... Therefore not recommended for most research purposes!). |
| Include lemma information: |
|
If set to 'yes', allows you to group collocates by lemma. [Caution: Note that grouping different word forms under one lemma is NOT always desirable. Many idiomatic phrases (e.g. 'He was in stitches' = 'he was laughing'; or 'He kicked the bucket') tend to take only one particular word form (cp. *'He was in stitch' or *'He kicks the bucket').] |
| Maximum window span: |
|
This sets the maximum collocational 'window span' and also applies it to the initial result. (It also forms the basis of the statistical calculations.) Choose from between 4 to 10 words (to the left and right) of the node/query word. (* N.B.: If you choose a large value now (e.g. '10'), it will then be possible to later reduce this span, whereas if you choose '4' now, you will not be able to extend the window later). However, choosing a large span at this stage will mean you potentially get more 'junk' results initially (a lot of false 'collocates' which occur far away from the node), so consider your options carefully.) The default value of '5' is suitable for most purposes. |
| Instances per page (for concordance display of individual collocations): |
|
Sets how many results you want displayed at a time (per screen) before you have to press 'Next Page'. |
|
Press this when you're done with the above options, to go to the next stage |
||
Step 3: You will now see some initial results for your collocational search, with the top part of the screen (the part above the orange row in the screenshot below) offering some further options:
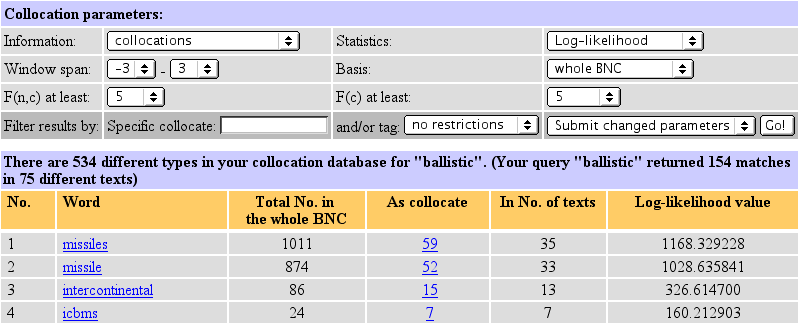
Clicking on the word in the 2nd column ('Word') will display more detailed information about the distribution of the collocate across the individual positions of the chosen window range. Also, the collocation values for all six statistical methods of calculation are given.
Clicking on the number in the 4th column ('As collocate') will display all sentences in which the word co-occurs with the node within the given window range.
The fifth column ('In No. of texts') indicates how many different texts the collocation occurs in. Some node-collocate pairs are highly genre-specific or may only be found in one particular text. The calculation of collocational strength does not take account of this. The range/dispersion information given in this column may therefore prove relevant in your interpretation of the results.
Setting Collocation Parameters |
The collocation parameters are explained in the following table:
| Option/Button | Explanation | Option/Button | Explanation |
| Information: |
Choose to display either the actual words which collocate
with your search word/phrase (the node) OR the POS-tags of these collocates:
[collocations | collocations on POS-tags] If you said 'yes' to "Include lemma information" during the previous step, you will find that you also have the following option: [collocations on lemma] This will group inflectional variants together, according to part of speech (e.g. working as an adjective is a different lemma from working as a verb) |
Statistics: |
Choose the type of statistic you want your collocations ranked by:
[Mutual Information | MI3 | Z-score | Log-likelihood | Log-log | Observed/expected | Rank by frequency] The default scoring method is Log-likelihood for new users of BNCweb. This statistical measure is suited to low-frequency items. |
| Window span: |
Change the window size or span (left & right context for the node).
If you used the default 'Maximum window span' during the previous step, this will range from -5 to +5. If you specified a different 'Maximum window span', however, this will show values for the range you chose (e.g. -10 to +10). |
Basis: |
Determines which frequency list (for F(c), see below) is used in the calculation of collocational strength.
Three choices are available:
[whole BNC | written texts only | spoken texts only] |
| F (n,c) at least: |
Frequency of the pair of items (node and collocate) occurring together
within the window/span chosen. This is essentially the same information as
in the column labelled As Collocate (the fourth orange-headed column
in the diagram above).
Choose a value between 1 -10, or else choose from 15, 20, 50, 100 |
F(c) at least: |
Frequency of the collocating word in the corpus as a whole (as a word in its
own right, regardless of combination or span). This is essentially the
same information as in the column labelled Total No. in the whole BNC
(the third orange-headed column in the diagram above).
Choose a value between 1 -10, or else choose one of the following values 15, 20, 50, 100, 500, 1000, 5000, 10000, 20000, 50000] |
| Filter Results by: |
Specific Collocate [ ]
This is optional. If desired, type in a specific word you want to set as the sole collocate for further analysis (choose from the ones displayed on screen or enter any other word) |
and/or tag: [ ]
(Optional) This can be used on its own, as a POS restriction on the collocates (to thin it down), or used in combination with the specific word typed into the box on the left. For e.g, you may want to thin/filter the initial results to show only the noun collocates of your node word |
Press the 'Go!' button once you've decided on any changes to
parameters or once you've specified a particular collocate or POS:
The drop-down menu allows you to do four things: (1) Submit changed parameters (Default) (2) Download all results (*N.B. This will simultaneously apply any changed parameters you have chosen) (3) do a Tag sequence search or (4) run a New Query. The last two save you having to go back to the main BNCweb start page. |
Collocation formulae |
In order to quantify collocational strength, BNCweb makes use of the following data:
The formulae for the calculation of collocational strength are as follows:
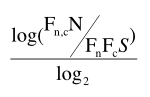
The disadvantage of this calculation method is that it gives too much weight to rare events (compare also the Log-log formula below).
In order to give more weight to frequent events, the F(n,c) on the top line of the MI formula was successively replaced by all powers of F(n,c) from two to 10. The cube of F(n,c) was empirically found to be the most effective coefficient, yielding the cubic association ratio (MI3). (Oakes 1998:171-72)
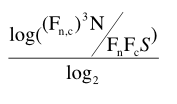
The probability of the collocate at any place where the node does not occur is expressed by:
![]()
The expected number of co-occurrences is given by:
![]()
The z-score is computed as follows:
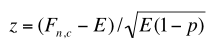
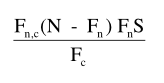
The Log-log formula proposed by Adam Kilgarriff is an extionsion of the Mutual information formula. In order to reduce the effect that co-occurring low-frequency items tend to receive higher collocation values, the Mutual information value is multiplied by log(F(n,c):
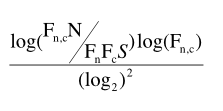
For the log-likelihood calculation, consider the following contingency table:
|
y |
not-y |
|
| x |
a |
b |
| not-x |
c |
d |
The collocation value is calculated as follows:
2*( a*log(a) + b*log(b) + c*log(c) + d*log(d)
- (a+b)*log(a+b) - (a+c)*log(a+c)
- (b+d)*log(b+d) - (c+d)*log(c+d)
+ (a+b+c+d)*log(a+b+c+d))
PLEASE NOTE: There is a small error in the way BNCweb
implements the log-likelihood formula: In principle, the calculation should be
strictly binary and the above formula therefore does not contain the variable "window span".
This is best illustrated with an example:
He said please please please leave me alone.
Here, the lexical item please co-occurs with leave three times within a window span of -3 to +3 words. In theory, the collocate
please should be only counted once (the binary options being "collocate present" and "collocate absent"). However, BNCweb
counts three occurrences of please in this sentence. As a result, the collocational strength of items which
co-occur repeatedly with the node item will be higher than it should be. In extreme cases, where the collocate is found more often than the
number of <s>-units containing the node-collocate pair, this will result in a mathematical error (calculation of the logarithm of a negative number).
These collocates will be displayed as the first items in the collocation table but no collocation value is given.
Notes |
Barnbrook, Geoff (1996) Language and Computers: A practical introduction to the computer analysis of language. Edinburgh: Edinburgh University Press.
Oakes, Michael P. (1998) Statistics for Corpus Linguistics Edingurgh: Edinburgh University Press.
More information concerning log-likelihood statistics can also be found in:
Dunning, Ted (1993) "Accurate methods for the statistics of surprise and coincidence" Computational Linguistics 19:1. 61-74.
| [ BNC query result | File and speaker information | Sort | Thin | Subcorpus | Distribution | Collocations | Tag sequence search | Delete hits | Save current hits | Download | Main page options ] |