| [ BNC query result | File and speaker information | Sort | Thin | Subcorpus | Distribution | Collocations | Tag sequence search | Delete hits | Save current hits | Download | Main page options ] |
Distribution |
The Distribution feature offers easy access to descriptive statistics concerning the distribution of your query result over the various metatextual categories encoded in the BNC. It saves you from having to perform several (or even dozens of) individual queries for a 'manual' compilation of the required statistics.
Performing a distribution analysis |
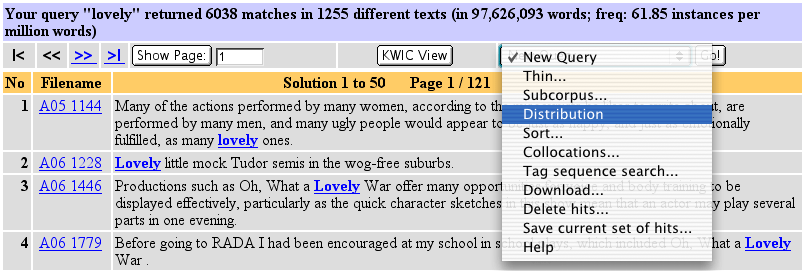
In the BNC Query Result window, select Distribution from the drop-down menu and press 'Go!' This is shown in the following screenshot of the results window after running a query for the word lovely:
After the calculation has finished, a page with the distribution of your query result over several major categories will
be displayed. Apart from the number of hits found in the individual catergories, the distribution feature also offers information about
the total number of words contained in these categories and the corresponding relative frequency of your query result.
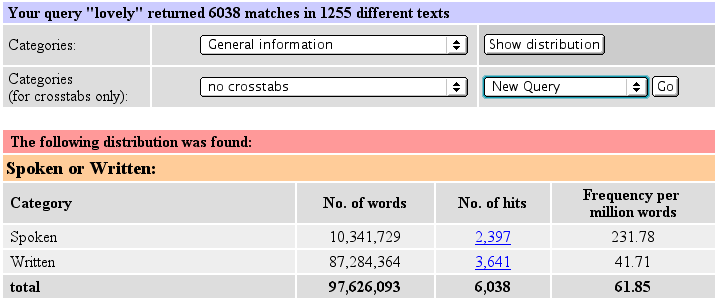
Relative frequency information makes it possible to directly compare data for different categories. This is shown in the following
screenshot: lovely is found more often in the written component (3,641 vs. only 2,397 hits in the spoken component),
but the relative frequencies reveal that lovely is in fact more than five times as frequent in the spoken data (232 vs. 42 instances
per million words).
Clicking on the number of hits in the third column will display all the sentences contained in the relevant category.
The upper drop-down menu on the top of the page allows you to choose from a list of other categories encoded in the header of the BNC texts. For example the category "Type of author" ('Sole', 'Corporate' or 'Multiple') is not shown on the default general information page. Select the desired category and press 'Show distribution'.
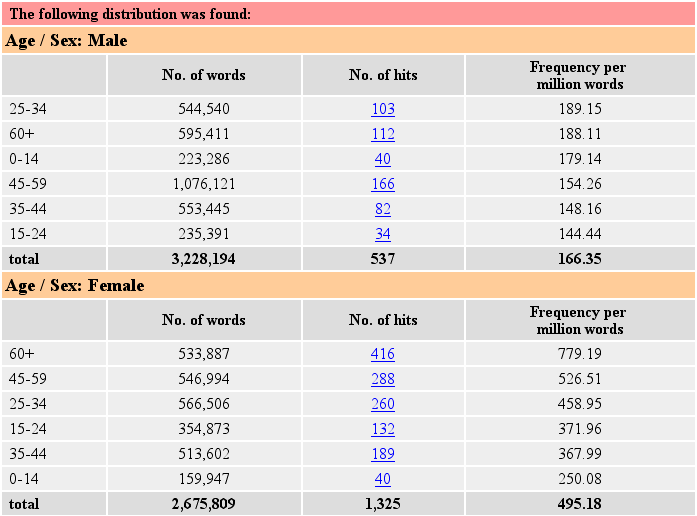
The lower drop-down menu can be used to display a crosstabulation of two different categories. In this way, it is for example possible to investigate the influence of the variables 'age' and 'sex' on the use of lovely in spoken English. As the following screenshot shows, men in general use lovely less often than women (166 vs 495 instances pmw). Men between the age of 24-35 use it most frequently but the differences between the age groups are not that great (between 189 and 144 instances pmw). With the female speakers, however, a clear connection between age and the use of lovely can be drawn: women aged 65 and over show a frequency of 779 instances pmw. This is more than three times as high as the frequency for the youngest age group (250 instances pmw). Without crosstabulation of data, such a correspondence might have gone unnoticed.
File frequency information |
Relative frequencies are useful for comparing different categories. But they may also be misleading as some words are highly genre-specific (and some specialized vocabulary may in fact be restricted to one single text). For example, the word homoeopathic has 216 occurrences in the whole BNC, which corresponds to 2.21 instances per million words. But how equally is it distributed? This question can be answered by selecting File frequency information in the upper drop-down menu. The result is shown below:
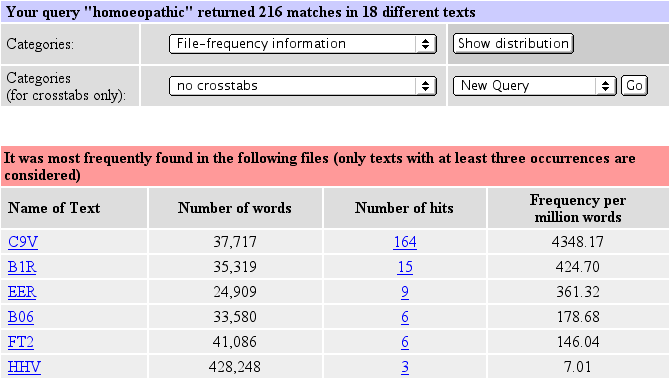
Over 75% of all occurrences of homoeopathic are found in a single text. As the File information page reveals, this is an extract from a text entitled "Homeopathy for everyone".
Notes |
KP3:2842 Oh, <name> oh, he's lovely, and <pause> disgusting. <unclear>.Is this his kind of ironic use also found in utterances of women aged 65+? Information like that obviously cannot be found in frequency tabulations. Corpus linguistics almost inevitably requires 'manual' work in order to get at meaningful interpretations. BNCweb reduces some of the necessary manual work, but it can't replace it.
| [ BNC query result | File and speaker information | Sort | Thin | Subcorpus | Distribution | Collocations | Tag sequence search | Delete hits | Save current hits | Download | Main page options ] |